近期許多人工智慧( AI )領域的科學家都在努力進行研究,大型語言模型 ( LLM ) 就是研究的成果之一,透過接受大量資料的訓練,可以辨識以及產生文字,甚至可以完成其他任務。然而近期 Meta 旗下的研究員公開表示,透過讓 LLM 一口氣預測多個 token ,可以提升 LLM 的準確性以及生成速度,大幅提升整體性能。
Meta 的研究員近期聯合巴黎高科陸橋大學、巴黎薩克雷大學的研究員,提出一種新的 LLM 訓練方式,透過一次性預測多個未來 tokens ,提高語言模型的樣本效率,與現在使用的一次預測一個 token 的自動回歸語言模型結構有著巨大的差異。 Meta 的研究員表示,在提供完全相同的數據集以及花費相同算的情況下,使用多 token 預測法就可以大幅提升 LLM 的性能。
《騰訊網》科技專欄作者「新智元」表示,現今較為知名的 LLM ,例如 ChatGPT 以及 LLaMA 等,都是透過預測「下一個 token 」的方式進行訓練。然而 Meta 研究員提出的多 token 語言模型是在 Transformer 架構下進行部分修改,該語言模型與以往單一輸出的模型不同,有 n個獨立的輸出 head 層,並預測下 n 個 token 進行運作。在 LLM 的推理過程中,每個 head 都能使用基本的 token 預測方法,透過多個 head 加速解碼的過程,可以將推理速度提升 3 倍。
「新智元」指出,研究員將多 token 與單一 token 兩種訓練方式的 LLM 進行對比,發現初始參數越多,多 token 訓練出來的 LLM 表現結果會越好。以 4 個 token 預測訓練為例,在 67 億以及 130 億參數的 MBPP 基準測試中,比單一 token 預測的 LLM 多解開 17% 的題目,而在 HumanEval 測試中也多解開 12% 的題目。
「新智元」表示,雖然多 token 預測訓練的 LLM 功能看似比單一 token 訓練者高,但並非適用於每種模型以及語言任務。同時,多 token 預測訓練也仍有進步空間,例如讓模型自動選擇每次需要預測多少 token 等。但這項研究也證明,有機會使用很低的成本,讓 AI 能夠執行高準確性的程式碼升成任務,也能加快 AI 的推理速度。另一方面,由於多 token 預測訓練仍保留大部分 LLM 的架構,與其他 Transgormer 模型區塊也具有相對較高的相容性。
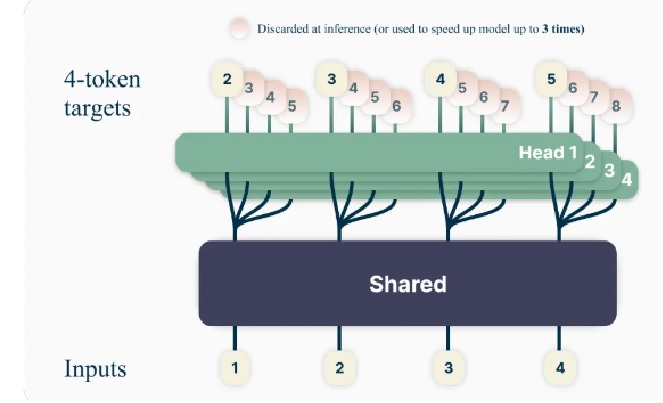
與以往的單一 token 預測模式不同,透過預測多個 token 出現多個獨立的 head 層,再預測多個 token ,增強 LLM 的性能。 圖:翻攝自 新智元