全球消費電子展(CES 2026)6 日登場,輝達(NVIDIA)與超微(AMD)接連由執行長黃仁勳與蘇姿丰發表主題演講,雙方不約而同將焦點鎖定「推理型 AI(Reasoning / Agentic AI)」與資料中心等級的運算基礎設施,宣告 AI 正從生成工具,邁向可長期運作、理解物理世界的關鍵基礎建設。
輝達執行長黃仁勳身著標誌性皮衣,再度站上 CES 主舞台,回顧過去一年 AI 產業的快速演進。他指出,隨著開源推理模型(如 DeepSeek R1)崛起,AI 擴散速度正以前所未見的節奏加快,產業關鍵已從「模型能不能做」轉向「能不能長時間、低成本地運行」。
全站首選:中國還沒到那水準! 10年前就要造「這戰機」仍不見影 若服役第一、二島鏈都危險
在此次 CES 上,輝達首度完整揭露新一代 Rubin 架構的效能數據,並以「推理時擴展(Test-time Scaling)」為核心概念,強調 AI 能力不再僅依賴訓練期擴模,而是透過推理階段投入更多算力與時間,換取顯著品質提升。

Rubin 架構整合 Vera CPU、Rubin GPU、NVLink 6、Spectrum-X 乙太網路、BlueField-4 DPU 與推理上下文記憶體儲存平台,目標在於顯著壓低推理成本、延長上下文處理能力。輝達指出,相較 Blackwell 平台,Rubin 可將推理 token 成本最高降低 10 倍,訓練 MoE 模型所需 GPU 數量減至四分之一。
其中,Rubin GPU 採用 NVFP4 精度,推理效能達 50 PFLOPS、HBM4 記憶體頻寬 22 TB/s,使單一 GPU 能承擔更多任務與更長上下文。NVLink 6 則讓 72 顆 GPU 以 3.6 TB/s 頻寬協同運作,如同「超級 GPU」。
針對長時間推理帶來的上下文儲存瓶頸,輝達同步推出由 BlueField-4 驅動的 推理上下文記憶體儲存平台,在 GPU 記憶體與傳統儲存之間建立高速「第三層記憶體」,可在特定場景下提升 token 處理量最高達 5 倍。
黃仁勳強調,AI 正從一次性聊天工具,演進為具備短期與長期記憶、能協作完成任務的智能體,這類 Agentic AI 必須建立在完整的系統級基礎設施之上。

黃仁勳強調,AI 正從一次性聊天工具,演進為具備短期與長期記憶、能協作完成任務的智能體,這類 Agentic AI 必須建立在完整的系統級基礎設施之上。
圖:達志影像/路透社輝達同時發表新一代 DGX SuperPOD,由 8 座 Vera Rubin NVL72 機架組成,總計 576 顆 GPU,並導入 Spectrum-6 交換晶片與共封裝光學(CPO)技術,進一步降低功耗與延遲,鎖定超大規模訓練與長時間推理場景。
微軟已承諾在下一代 Fairwater AI 超級工廠中部署數十萬顆 Vera Rubin 晶片,CoreWeave 等雲端業者亦預計於 2026 年下半年提供 Rubin 實例服務。
另一邊,AMD 董事長暨執行長蘇姿丰在 CES 2026 主題演講中指出,AI 使用者自 ChatGPT 問世後已由百萬暴增至逾 10 億人,未來有望突破 50 億,AI 正從工具正式轉型為全球基礎建設。
她預估,全球算力需求將在未來五年由 Zetta 等級推升至 10 YottaFLOPS,相較 2022 年成長達一萬倍,製程與封裝技術將成為決勝關鍵。

AMD 首度公開 2 奈米 EPYC Venice 伺服器處理器,採用 Zen 6 架構,單顆最高 256 核心,為首款採用台積電 2 奈米製程的 HPC 產品。AI 加速器方面,AMD 發表 Instinct MI455X,整合 2 奈米與 3 奈米 chiplet、HBM4 記憶體與 3D 封裝,電晶體數達 3,200 億顆,推論效能較前代提升最高 10 倍。
AMD 同步推出 Helios 機櫃級 AI 平台,整合 MI455 GPU、Venice CPU 與 Pensando 網通晶片,72 顆 GPU 可如單一運算單元運作,單一機櫃即可提供 2.9 ExaFLOPS 運算效能,鎖定超大規模資料中心。
業界普遍認為,AMD 此舉不僅直接挑戰輝達在 AI 資料中心的主導地位,也凸顯台積電在 2 奈米製程與先進封裝(SoIC、CoWoS)上的戰略地位,正式躍升為 AI 時代的核心供應鏈關鍵。
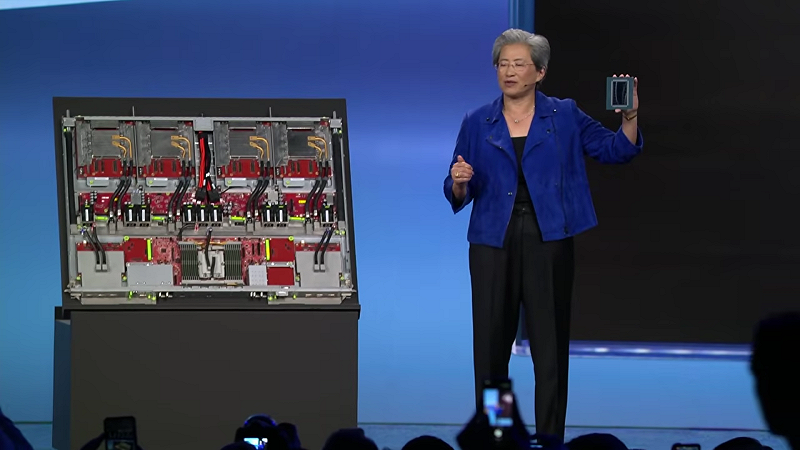
業界普遍認為,AMD 此舉不僅直接挑戰輝達在 AI 資料中心的主導地位,也凸顯台積電在 2 奈米製程與先進封裝(SoIC、CoWoS)上的戰略地位,正式躍升為 AI 時代的核心供應鏈關鍵。 圖:翻攝自CES YouTube