

由人工智慧研發團隊 DeepMind 發表的 AlphaZero 登上最新一期《科學》雜誌封面。這已經不是 DeepMind 第一次登上國外權威雜誌的封面,每一次 DeepMind 被報導都會獲得人工智慧學界的一陣歡呼,這次更是如此。同時擊敗圍棋、將棋、西洋棋最強 AI 的 AlphaZero ,被認為可能代表著深度學習 AI 的終極解答。
《科學》雜誌表示,如果人們想透過一套計算方式去解決多個不同的複雜問題,那麼唯一能夠達成這目標的辦法就是,創造一個自主學習的人工智能系統,讓它自行學著去解決問題。而 AlphaZero 辦到了。

▲(圖/翻攝自 fossbytes )
根據 DeepMind 的介紹, AlphaZero 使用完全無需人工特徵、無需任何人類棋譜、甚至無需任何特定最佳化的通用強化學習演算法。舉例來說,由於圍棋的規則明顯和其他棋類如西洋棋、將棋不同,像是圍棋的每一子都是完全相同的、且棋盤也是完全對稱的。
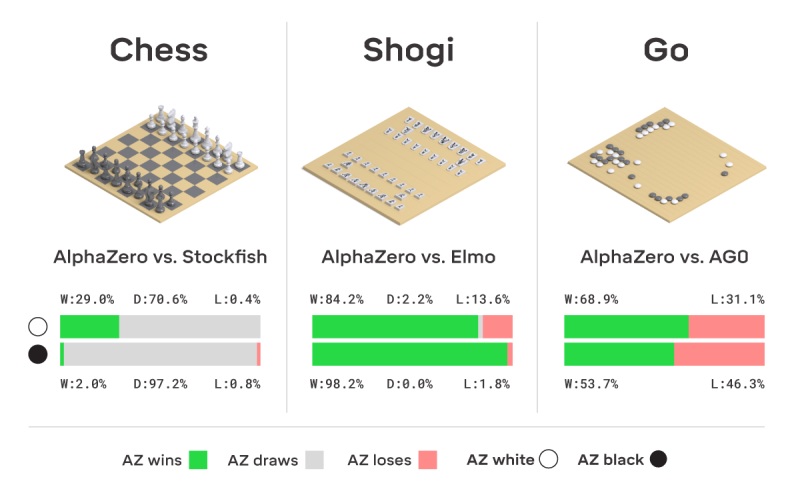
為了因應圍棋的特殊性, AlphaZero 的前身 AlphaGo Zero 便有設計專為圍棋使用的特殊計算程式。但 AlphaZero 沒有,作為一個「通用型」學習 AI , AlphaZero 完全僅依靠深度神經網絡和蒙特卡洛搜索樹算法的自我學習。在完全沒有輸入人類的棋譜、沒有輸入特別設計的專用計算程式的情況下,只藉著自我對弈的不斷學習, AlphaZero 就已經能夠分別在圍棋將棋西洋棋擊敗了原本的世界最強 AI 。
而且, AlphaZero 打敗原本的西洋棋世界最強 AI 只花了 4 小時學習,打敗原本的將棋世界最強 AI 只花了 2 小時學習。打敗原本的圍棋世界最強 AI 只花了 30 小時學習。 AlphaZero 最大的特色就是可以學會並精通不同的棋類競賽,而且它每一步棋所須計算的可能性變化,比之前的 AI 要來得少許多。換句話說, AlphaZero 並不是去無限量的計算棋盤所有可能性,而是透過自己的深度神經網絡研判,專注於小範圍的計算。

當前熱搜:陷黃金詐騙賭局 房子慘遭抵押 豐原5口命案死因曝光
▲(圖/翻攝自 DeepMind 網站)
這樣的「思考模式」,其實正和一般人類棋士無異。西洋棋前世界冠軍 Garry Kasparov 就表示, AlphaZero 的下棋風格靈活多變,「和我很像!」,且不同於其他 AI 程式傾向保守的先求立於不敗, AlphaZero 非常具有侵略性,更喜歡冒險。傳統的人工智慧程式在下棋時,憑藉強大計算能力很少犯錯,但在面對不清楚「該計算什麼」的局面時,便容易出現失誤。反觀 AlphaZero ,它呈現出的是一種「感覺」、「洞察」,一種對棋盤上局勢發展的直覺。
曾和 AlphaGo Zero 對奕的圍棋棋士李世石便說過「我改變了看法, AlphaGo Zero 不只是機器,它具有創造性」。而現在同時精通圍棋將棋西洋棋的 AlphaZero ,顯然擁有更強更靈活的創造能力。
過往的人工智慧程式,往往只能精通專一領域,只能處理特定情境的問題。但 AlphaZero 不同,它能夠適應各種規則。這讓人相信,未來可以將這深度自主學習的 AI 能力,運用在其他問題上。比如說, DeepMind 團隊開發的最新家族成員 AlphaFord ,便是投入在學習基因序列的蛋白質結構相關問題。假如在此領域 AlphaFord 也能獲得驚人成就,那可不同於在棋類競賽贏過對手,將會真正替人類社會帶來巨大改變。
下一次登上封面的會否就是 AlphaFord ?深度學習的人工智慧究竟能發展到何種里程碑,讓我們一起期待吧。
延伸閱讀:



















